9月15日,2020腾讯AI Lab犀牛鸟专项研究计划结题评优交流会举行。我院信息科学与技术学部郑海涛副教授负责的项目“融合多类型多知识结构的预训练神经网络语言模型”荣获技术创新奖,吴志勇副研究员负责的项目“面向高品质歌声合成的神经网络参数化音高精细建模研究”荣获优秀奖。
“融合多类型多知识结构的预训练神经网络语言模型”是清华大学和腾讯AI LAB的联合项目,从多个角度探索预训练语言模型对复杂语言知识的理解、分析、计算和生成能力,相关研究成果在ACL、EMNLP、AAAI等自然语言处理以及人工智能顶级会议上发表论文。项目具有多项创新点,首先,该项目融合了词法、句法等多层语言学知识,并通过对比学习提升了语言模型的对抗鲁棒性和语义敏感性,提出了负语义对比学习方法(Contrast LearnIng with semantic Negative Examples, CLINE),该方法在无监督的情况下构造语义否定例,提高语义对抗攻击下的鲁棒性,有效地感知微小扰动引起的语义变化,同时保证语义敏感性和对抗鲁棒性。其次,该项目设计了一种变分生成聚类算法,用于从读者评论中进行潜在语义学习和主题挖掘,融合用户隐知识,并通过挖掘用户评论中主题知识,提升语言模型对复杂概念的理解和生成能力。该项目还通过自动构造不同难易程度的训练样本,提升模型的细粒度语义识别能力,采用现成的响应检索模型和响应生成模型作为自动灰度数据生成器,使匹配模型捕捉更细粒度的上下文与会话的相关性差异,并减少模型在训练阶段和测试阶段面临的干扰强度的差异。
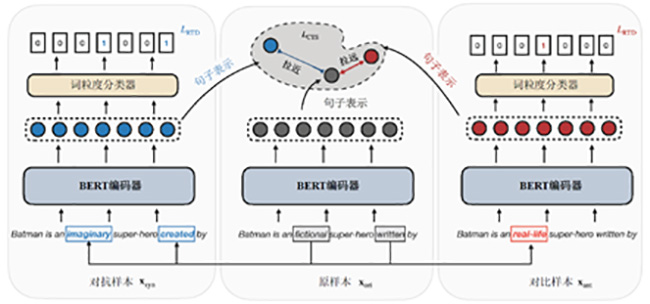
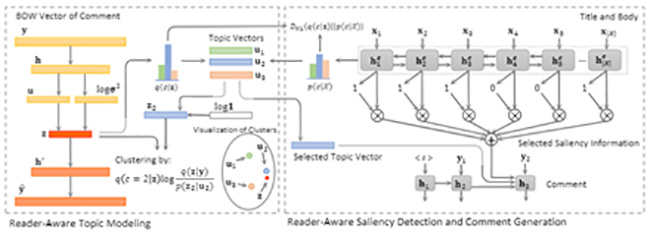
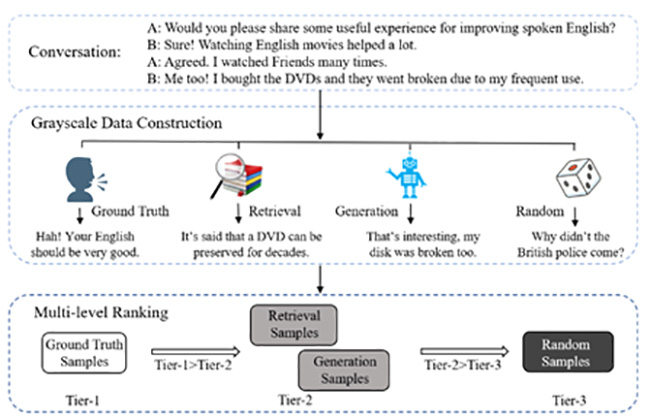
“融合多类型多知识结构的预训练神经网络语言模型”项目技术框架图
“面向高品质歌声合成的神经网络参数化音高精细建模研究”项目提出基于精确时长及音高建模与控制的神经网络歌声合成方法,综合上下文、音素、歌者等多方信息,确保能做出符合歌者自身特点的时长、音高预测,增强合成歌声自然度。音高和时长的多变性是歌声合成和不同于语音合成的地方。为了能生成吐字清晰、不跑调、富有表现力的歌声,该研究在传统语音合成模型的基础上,提出了一种基于精确时长和音高建模与控制的歌声合成解决方案,具有诸多特点和优势,如:结合上下文、当前音素、乐谱、歌者多方面信息来预测每个音的持续时长,实现具有不同歌者个性化特征的时长建模;针对不同歌者的唱法技巧,考察倚音、滑音、颤音等不同装饰音的歌曲上下文依赖性,构建了更为精确的音高模型。与现有方法相比,本项目提出的方法加强了对时长、音高的建模,增强了歌声合成的可控性,实现了更加标准流畅的合成歌声。
项目培养实习生2人,并发表音频处理领域顶级国际学术会议论文2篇,申请发明专利1项。项目成果可用于虚拟歌姬、数字音乐创作、音乐教育等多种多样的应用场景中。
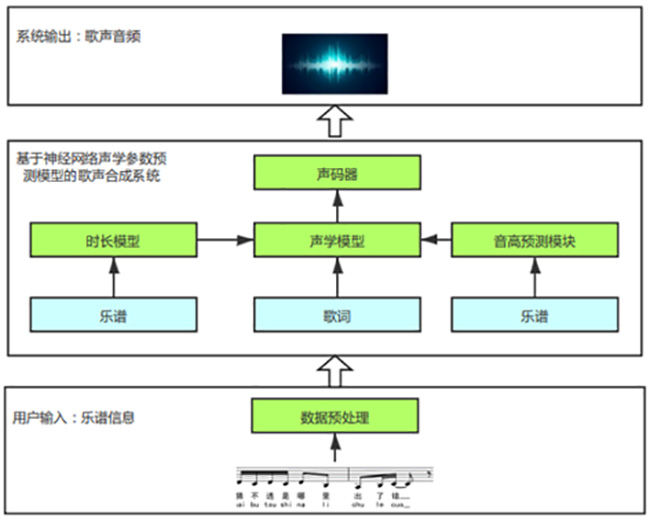
“面向高品质歌声合成的神经网络参数化音高精细建模研究”项目技术框架图
腾讯AI Lab犀牛鸟专项研究计划旨在支撑腾讯AI Lab与学界合作,探索AI各主要领域的学术前沿和技术应用。自2017年开展以来,累计支持科研项目150余项,覆盖海内外重点高校50余所。该计划每年定期开展,一般于十二月份开放申请,次年三月份公布入选项目,立项后开展为期一年的合作,并于秋季召开结题评优交流会。
吴志勇参与创立的清华大学人机语音交互实验室(THUHCSI)与腾讯AI Lab多年来保持合作,取得了多项研究成果。其实验室主导的“可控的端到端表现力可视语音合成技术研究”项目获得2019年度腾讯AI Lab犀牛鸟专项研究计划卓越奖。
来源:信息科学与技术学部
编辑:叶思佳
