

Recently, six papers from the Division of Information Science were accepted into the 2021 AAAI Conference on Artificial Intelligence. The Association for the Advancement of Artificial Intelligence (AAAI) is a major academic organization in the field, and the annual conference aims to promote research and scientific exchange among artificial intelligence researchers, practitioners, scientists, and engineers in affiliated disciplines.
This year, the AAAI Conference received over 9000 submissions and accepted 1692 papers. Co-chair Kevin Leyton-Brown from the University of British Columbia commented that papers were on an “amazingly high-technical level”, acknowledging the high quality of this year’s papers.
Generating Diversified Comments via Reader-Aware Topic Modeling and Saliency Detection
Author: Wang Wei, PhD student, Advisor: Zheng Haitao
This paper proposes a unified reader-aware topic modeling and saliency detection framework for automatic comment generation. Wang designs a variational generative clustering algorithm for topic mining from reader comments, and introduces Bernoulli distribution estimation to select saliency information in news content. Obtained topic representations and selected saliency information are then incorporated into a decoder to generate diverse and informative comments.
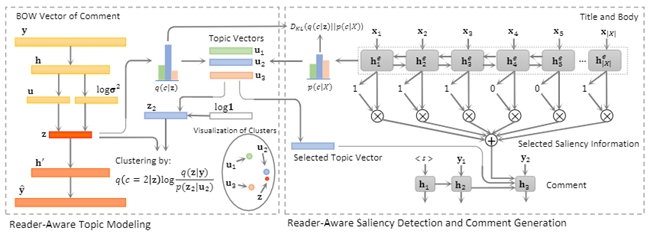
Generation of diverse comments through reader-aware topic modelling and saliency detection
Inferring Emotion from Large-scale Internet Voice Data: A Semi-Supervised Curriculum Augmentation based Deep Learning Approach
Author: Zhou Suping, Ph.D. student, Advisor: Jia Jia, Co-advisor: Wu Zhiyong
Effective analysis of user emotion can help intelligent voice assistants, such as Siri, provide better services. This paper proposes a novel semi-supervised multi-modal curriculum augmentation deep learning framework to infer emotion from large-scale internet voice data. Zhou designs a curriculum learning based epoch-wise training strategy, which first trains the model with strong and balanced emotion samples from acted voice data, and then with weak and unbalanced emotion samples from internet voice data. It takes advantage of large-scale unlabeled data in real-world datasets, and introduces a Multi-path Mix-match Multimodal Deep Neural Network (MMMD), to effectively train labeled and unlabeled data in hybrid semi-supervised methods for superior generalization and robustness. Experimental results on an internet voice dataset and an acted corpus have proven the effectiveness of the proposed approach.
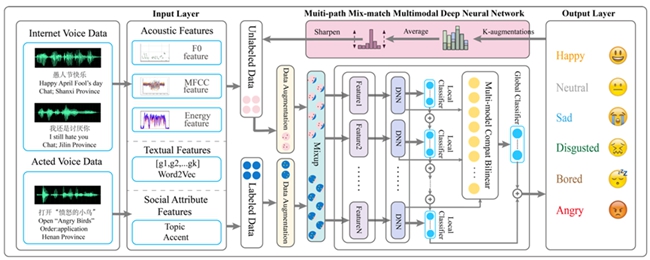
Structure diagram of the semi-supervised speech emotion analysis model
Knowledge Refinery: Learning from Decoupled Label
Author: Ding Qianggang, Master’s student, Advisor: Xia Shutao
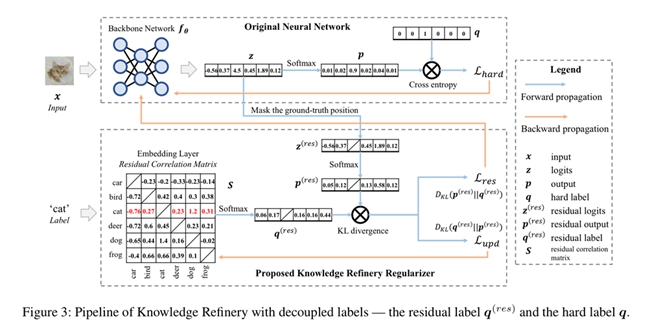
Recently, a variety of regularization techniques have been widely applied in deep neural networks, such as dropout, batch normalization, weight normalization, and so on. This paper proposes a method called Knowledge Refinery (KR), which enables the neural network to learn the relation of classes without the tedious teacher-student two-stage training strategy. Ding proposes the definition of decoupled labels, which consists of the original hard label and the residual label. To exhibit the generalization of KR, the method is evaluated in both fields of computer vision and natural language processing. Empirical results show consistent performance gains under all experimental settings.
How does the Combined Risk Affect the Performance of Unsupervised Domain Adaptation Approaches?
Author: Zhong Li, Master’s student, Advisor: Yuan Bo
Based on the upper bound of unsupervised domain adaptation (UDA), many unsupervised domain adaptation (UDA) algorithms have been proposed. However, these algorithms only consider the first two terms in the theoretical bound: source domain risk and distribution discrepancy. Existing algorithms ignore the last term (combined risk) in the bound since it is difficult to estimate the combined risk without the labels of the target data. This paper proves that the combined risk is closely related to conditional distribution discrepancy, and that the combined risk is of importance to UDA. It also proposes a proxy to estimate the combined risk and a double loss bound to improve the performance of domain adaptation. Extensive experiments prove that the proposed method (E-MixNet) has achieved state-of-the-art effects on three public data sets. Adding the proposed proxy to four representative methods of unsupervised domain adaptation was able to improve performance up to 5.5%.

The combined risk and double loss bound
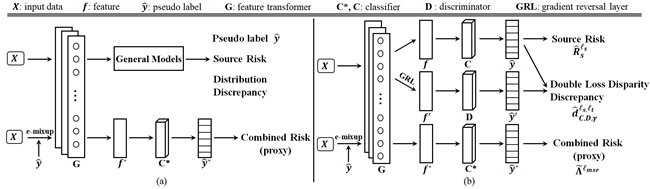
The network structure
Learning to Augment for Data-Scarce Domain BERT Knowledge Distillation
Author: Feng Lingyun, Master’s student, Advisor: Zheng Haitao
Pre-trained language models such as BERT and XLNet have demonstrated their superior performance in natural language processing tasks. However, parameters of the models are rather large, making them difficult to deploy in resource-constrained scenarios. A typical solution is to adopt knowledge distillation, but when the target domain data is scarce, the student model cannot learn sufficient knowledge from the teacher model. This paper proposes leveraging resource-rich source domain data to help augment target data, and adopting a reinforced data selector to refine the augmentation strategy based on the performance of the student model. Experimental results show that the method significantly improves the performance of the student model, especially for data-scarce domains.
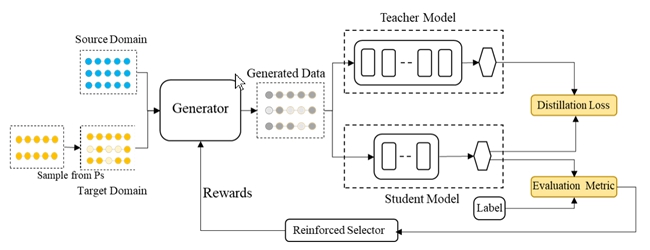
The automatic data augmention model structure
Weakly Supervised Deep Hyperspherical Quantization for Image Retrieval
Author: Wang Jinpeng, Master’s student, Chen Bin, Ph.D. student; Advisor: Xia Shutao
Quantization is a kind of hashing method to improve the efficiency of large-scale image retrieval. Many deep quantization methods have achieved state-of-the-art performance, but often require a lot of manually labeled training data and hinders the application of quantization in label-hungry scenarios. In their new paper, Wang and Chen et al. propose a weakly supervised deep quantization method that utilizes web images with noisy tags as training data. They designed an embedding-based tag relation graph to extract the semantic information of tags. Guided by such information, a semantic quantization encoder in a hyperspherical space learned to produce semantic quantized representations for images. Extensive experiments on two large-scale web image datasets show that the new method performed better than existing advanced weakly supervised deep hashing methods.

Writers:Wang Wei, Zhou Suping, Ding Qianggang, Zhong Li, Feng Lingyun, Wang Jinpeng, Chen Bin
Editor: Karen Lee
