近日,我院信息科学与技术学部夏树涛/江勇教授团队、王好谦教授团队和袁春副研究员团队的4篇论文被机器学习领域国际顶级会议神经信息处理系统大会(Neural Information Processing Systems, NeurlPS)2021接收。

白杨(左)、严欣(右)
2017级计算机科学与技术专业博士生白杨(指导老师:江勇)和2019级计算机技术专业硕士生严欣(指导老师:夏树涛)发表论文《对抗鲁棒模型的聚类现象》(Clustering Effect of Adversarial Robust Models)。该论文通过系统地分析基于对抗训练的对抗鲁棒模型和通过标准训练的非鲁棒模型在其线性子网络上的统计规律,在对抗鲁棒模型中发现了一个有趣的层次聚类现象。基于此,研究团队提出了一种对对抗鲁棒性的新颖理解,并将其应用于更多任务,包括鲁棒性提升和域适应。
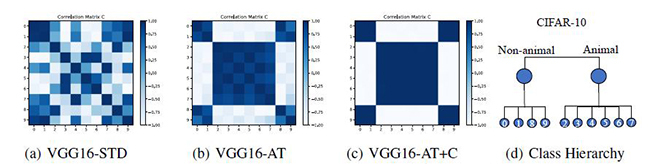
基于CIFAR-10数据集训练的VGG-16模型的关联矩阵图:图(a)’STD’代表非鲁棒模型,图(b)’AT’代表对抗鲁棒模型,图(c)’AT+C’代表运用层级聚类的对抗鲁棒模型, 图(d)展示CIFAR-10数据集的分层标签
随着对对抗样本的进一步研究,对抗鲁棒性越来越受到关注。对抗鲁棒模型和非鲁棒模型相比,对抗鲁棒模型通过将对抗样本加入到神经网络模型训练中以增强模型的鲁棒性。现有的工作表明,对抗鲁棒模型不仅在对抗性攻击评估下表现出色,并有助于提高一些下游任务的性能,但对于对抗鲁棒模型底层机制的理解仍不明晰。为了探究对抗鲁棒模型和非鲁棒模型的差异,研究团队提取神经网络的线性子网络(指的是在原网络的基础上去除掉批处理(BN)、激活层(RELU),使用平均池化层代替最大值池化层)来探究整个网络的数据特性。研究发现,对于对抗鲁棒模型和非鲁棒模型,对抗鲁棒模型表现出明显的权重层级聚类现象。基于这些观察,团队提出了一种插入式层次聚类训练策略,进一步增强对抗鲁棒模型的鲁棒性。同时,他们也探究了一些有趣的对抗性攻击现象:除了与对抗性相关的研究外,团队还通过对层次聚类的理解进一步探索了一些下游任务,如域适应。实验结果表明,在多个公开数据集中对抗鲁棒模型学习的聚类效果和层次分类有利于域适应任务。

蔡元昊
2020级人工智能项目硕士生蔡元昊(指导老师:王好谦)《基于像素级噪声感知的对抗训练学习生成逼真的噪声图像》(Learning to Generate Realistic Noisy Images via Pixel-level Noise-aware Adversarial Training)。该论文基于真实噪声场景定义一个像素级的噪声模型提出图像去噪方法,并提出了一个噪声可感知的对抗生成网络。
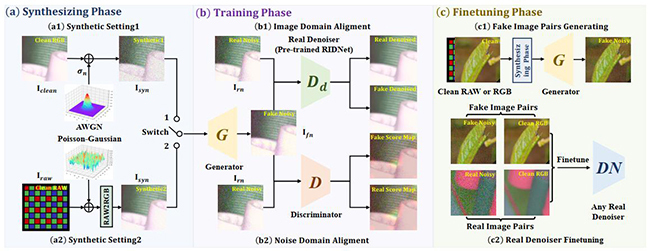
方法框架
图像去噪任务主要是将单张带噪点的给定图像的噪声去除。相机或智能手机在捕获图像的过程中不可避免地会引入噪声,这些噪声的存在严重降低图像质量,使其视觉效果变差,同时严重影响下游识别、检测、分割算法的性能。因此,图像去噪任务便显得尤为重要。传统去噪方法大多基于手工设计的图像先验或者数学假设,这类算法的表征能力和泛化性能较差。随着卷积神经网络的发展,图像去噪任务的主流方法逐渐被深度学习占领。然而,深度学习需要大量的噪声-干净图像对,通过摄像设备获取干净图像的过程费时费力,通常是对同一场景连续拍摄上百张图像之后取均值来获得干净图像。在拍摄过程中如果存在抖动、场景变化、光照条件改变等,还会导致捕获的干净图像质量受损,因此基于深度学习的图像去噪算法面临着十分严峻的数据短缺问题。为解决这一个数据短缺问题,团队提出了PNGAN方法,该方法大致分为三个阶段:第一阶段是噪声的合成,分两种设置,一种设置就是高斯噪声,另一种设置是泊松-高斯噪声;第二阶段是对抗生成网络的训练,利用一个预训练好的去噪网络作为正则化器来辅助生成网络与像素级判别器的对抗训练;第三阶段是微调阶段,在把第二阶段的生成器训练好之后,用其在高清数据上生成噪点,创造出更多的噪声-干净数据对,将这些数据对加入去噪网络训练的数据池当中,以提升去噪模型的性能与泛化性。

边豪(左)、陈扬(中)、邵朱晨(右)
2021级人工智能项目硕士生邵朱晨、边豪和陈扬(指导老师:王好谦)发表论文《基于Transformer的多示例学习算法在组织病理学图像分类中的应用》(TransMIL: Transformer based Correlated Multiple Instance Learning for Whole Slide Image Classification)。该论文针对组织病理学的弱监督分类问题提出了一种新的关联性多示例学习理论,并提供了相应的证明。基于这一理论,论文进一步设计了一种基于Transformer的多示例学习算法,它同时探索了形态学和空间信息,可有效地处理不平衡/平衡和二元/多元分类并具有可解释性,并在三个公开的病理图像数据集上取得最优性能。
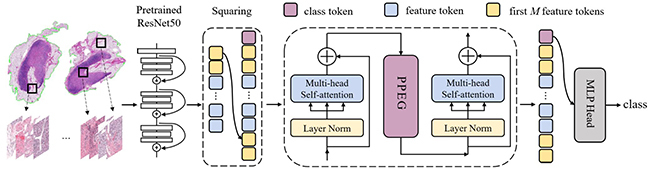
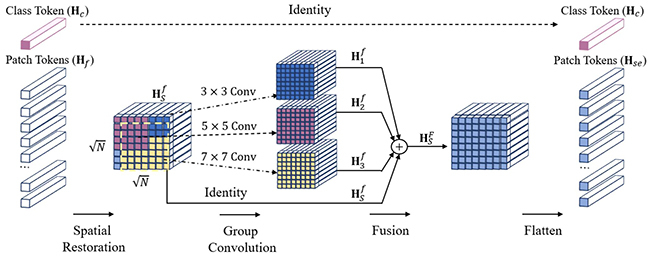
方法框架
活检诊断是癌症治疗和研究流程的基本步骤,是癌症诊断的“金标准”,其中活检样本的阴阳分类和癌症亚型分类,对患者疾病的精准诊断以及预后治疗有重要作用。组织病理图像扫描仪的出现为病理图像分析开辟了新的可能性,可将活检载玻片上的组织转换成千兆像素的组织病理图像(WSI),充分保留了原始的组织结构。考虑到组织病理学巨大的尺寸以及像素级的注释通常难以获得,当只有诊断级别标签时,组织病理图像的分析便属于一种弱监督学习问题。但是目前的多实例学习方法通常是基于独立同分布假设,忽略了不同实例之间的相关性。为解决这个问题,本文提出了一个新的理论:关联性多实例学习理论,并进一步设计了一种基于Transformer 的多实例学习方法,它同时探索了形态学和空间信息。其中由于Transformer本身不具备对于序列顺序信息的关注能力,因而通常采用位置编码来利用序列的顺序信息。在组织病理学领域中,因为组织病理图像大小本身不固定,且不同组织病理图像中组织区域面积不同,所以对应序列的片段数量往往不相同。本文的PPEG模块在同一层使用不同大小的卷积核,既可以编码较为稀疏的位置信息,也可以编码较为紧密的位置信息,使PPEG模块对于不同类型的组织病理图像更具有普遍的适应性。最终,本文的算法在三个公开的组织病理图像数据集中取得了最优性能。

许正卓(左)、柴增豪(右)
2020级计算机技术项目硕士生许正卓、柴增豪(指导老师:袁春)发表论文《在长尾视觉识别中构建校准能力更好的模型》(Towards Calibrated Model for Long-Tailed Visual Recognition from Prior Perspective)。该论文主要关注在长尾数据监督下模型性能和校准能力较差的问题,从先验的角度提出两种解决策略同时提高模型的准确率和校准能力。

错分矩阵展示:对角线元素表示正确分类,非对角线表示错分情况,横坐标为真实标签,纵坐标为预测标签
自然的数据通常存在严重的类别不平衡问题,分布上呈现“长尾”的情况,即大多数样本属于极个别类别,而大多数类别拥有的样本数量很少。Mixup是一种常见的数据增强方法,在均衡数据上可以有效改善模型的特征学习,并且可以提升模型的分类校准能力。然而,研究团队观察到Mixup在长尾分布的数据上并没有体现出明显的作用,对模型的分类校准也没有明显的帮助。因此他们从先验概率的角度出发,采用了尾部数据偏好的混合因子和对应采样规则,构建了数据均衡的混合形式,从而改善了Mixup在长尾数据上的表现。研究团队还指出,被长尾数据监督训练的模型都存在一个因为标签先验不同而导致的固有偏置,因此,他们在标准的交叉熵损失上补偿了这一偏置,并证明了这一改动是符合模型校准的。实验结果表明,上述两个改动都可以进一步提升模型的性能,它们的组合还可以达到前沿水平,并且可以无需后处理地提升模型的校准能力。
文/图:信息科学与技术学部
编辑:余飞慧
