我院袁春教授团队在长尾数据下的标签噪声问题的最新研究成果,以“When Noisy Labels Meet Long Tail Dilemmas: A Representation Calibration Method”为题,被计算机视觉领域世界三大顶级会议之一的ICCV 2023录用,获得最佳论文提名奖。ICCV 2023有效投稿数为8260篇,其中最佳论文提名的仅有17篇(入选率0.2%)! ICCV,英文全称International Conference on Computer Vision,中文全称国际计算机视觉大会,由IEEE主办,每两年在世界范围内召开一次,得到世界各地研究者的高度认可。
深度学习在许多领域取得了快速进展,这很大程度得益于大规模和高质量的标注数据集,而在现实中我们很难获得如此完美的数据集。这来源于两个方面,一是部分数据标注错误,二是数据类别不平衡,呈现出长尾分布。在现实环境中,两种不完美的情况通常同时存在。深度神经网络具有强大的拟合能力。网络在带有不平衡且带错误标签的数据集上进行训练,会导致网络过拟合,进而严重降低模型的泛化性能。虽然长尾分布学习和标签噪声学习都已经有了一定的研究,但是这种更加实际且具有挑战性的长尾数据下的标签噪声任务却未被充分探索。
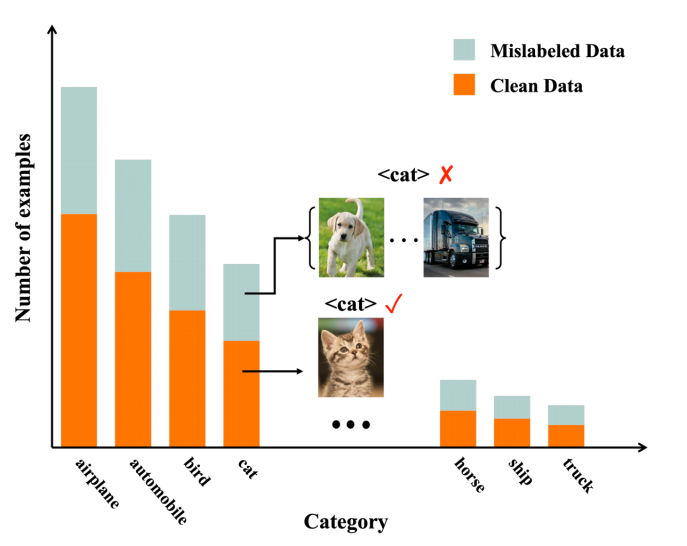
图1 长尾数据下的标签噪声问题示意图
最直观解决这个复合问题的方法是将标签噪声学习的算法和长尾数据学习算法进行复合。然而通过调研相关文献,发现算法的简单复合并不能有效解决这一具有挑战性问题,主要有以下挑战点:(1)如何在带有错误标注的数据中去学习到“真实”的长尾数据分布。(2)如何将尾部类数据与错误标注的样本进行区分。因此,针对以上挑战,袁春教授团队提出了深层表征校准方法RCAL。该方法的目的是希望从深层表征的角度去还原潜在的平衡且干净的数据分布,并提供正确的信息帮助网络训练。
该研究的方法由三部分组成:对比学习预训练、分布校准和个体校准。
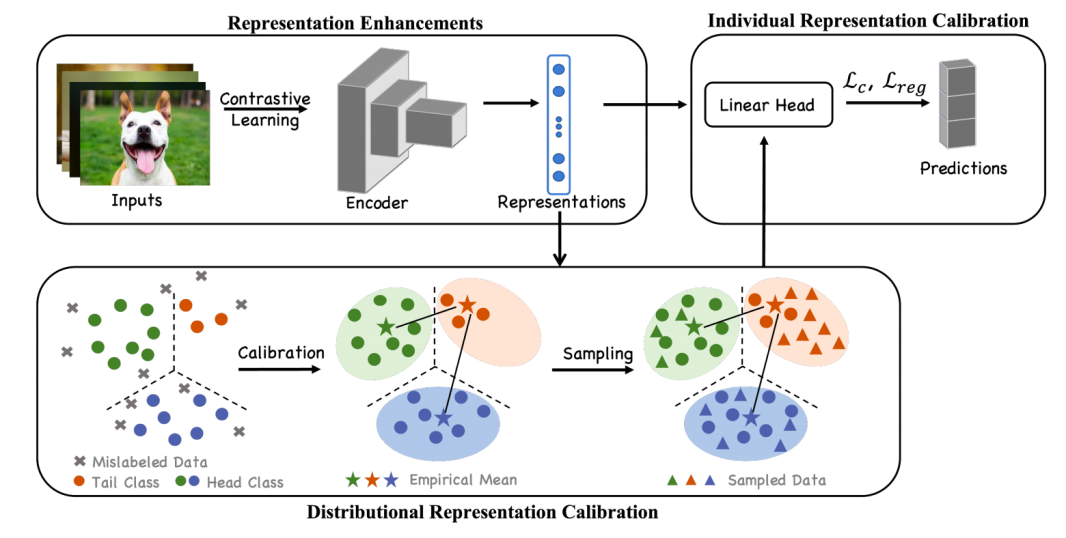
图2 算法总流程示意图
第一步,采用对比学习进行预训练以获得原始数据的深层表征,该表征可以捕获同一类内的相似特征并学习不同类之间的可鉴别特征。使用对比学习的原因是,它是一种自监督的方法,不受噪声标签的影响。此外,其学习到的特征可以表现出聚类特性,为后续操作提供支持。
第二步,经过对比预训练后,进行分布校准以减轻噪声标签和长尾问题。该方法基于这样的假设:在数据污染之前,每个类数据的深层表征满足一个多元高斯分布。基于此,可以估计每个类别的均值和协方差矩阵,以进行后续的校准。
具体来说,首先在深层表征上使用异常值检测算法,以识别可能不正确的标注数据并将其删除。然后,可以估计每个类别的均值和协方差矩阵。对于样本量较小的尾部类,进一步使用与其接近的头部类信息来帮助其估计。获得每一类分布后,对这些高斯分布进行重新采样,以减轻类别不平衡。
第三步,联合采样数据和原始数据集训练最终的分类器。同时,将fine-tune得到的表征与对比学习学到的表征的距离作为正则化项,以保留通过对比学习学到的知识。最终的目标函数是在校准数据集上评估的交叉熵损失加上正则化项。
从实验上,在合成的CIFAR-10和 CIFAR-100数据集上,该研究观察到在不同的噪声率和不平衡率下,RCAL几乎可以超越所有基线。随着任务更具挑战性,RCAL表现出更明显的优势。
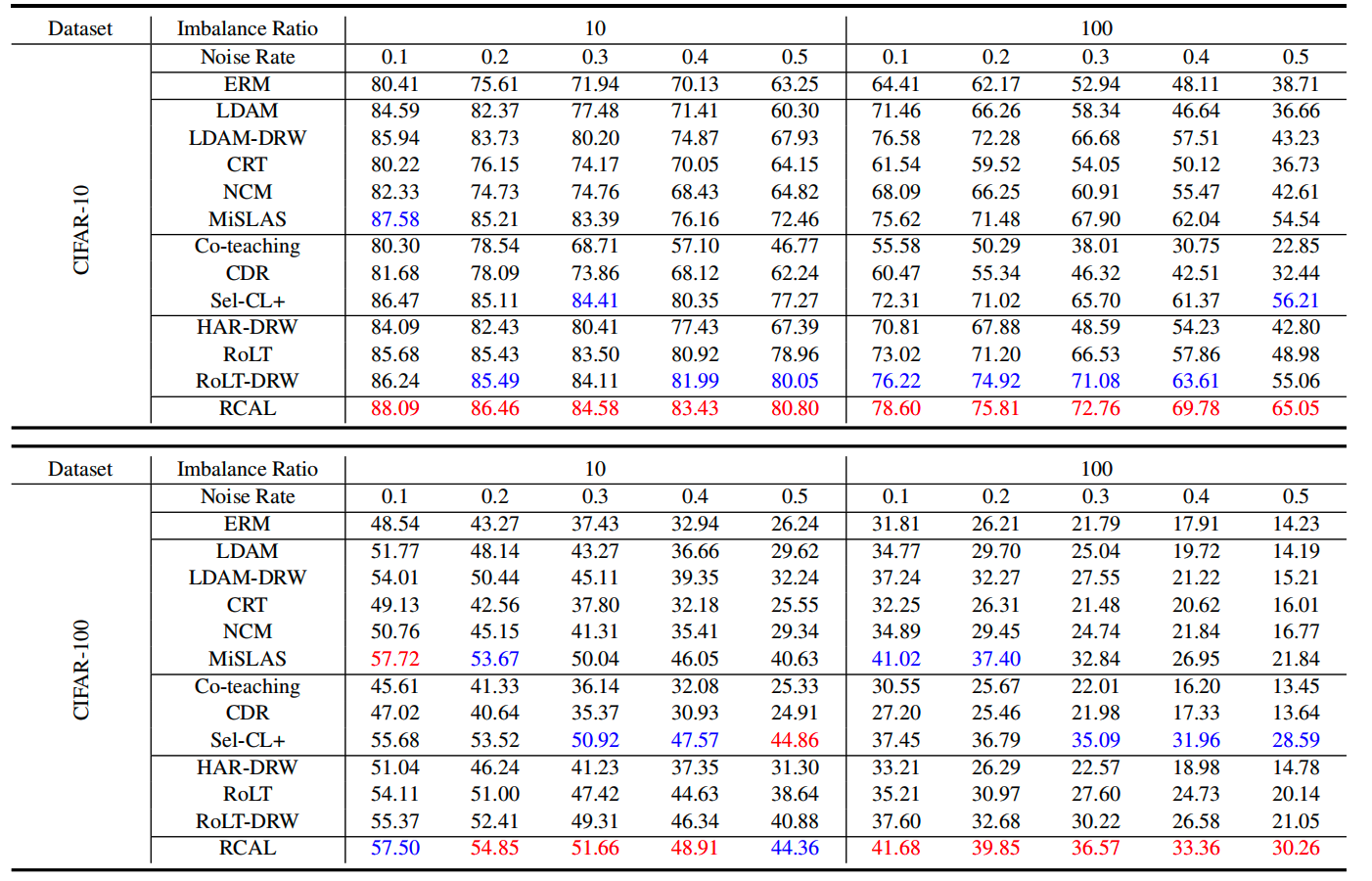
图3 CIFAR-10、CIFAR-100 合成数据下的测试准确度
在真实数据集上可以看出,与其他最先进的方法相比,RCAL+在 WebVision验证集和 ImageNet ILSVRC12验证集上均取得了最佳结果。
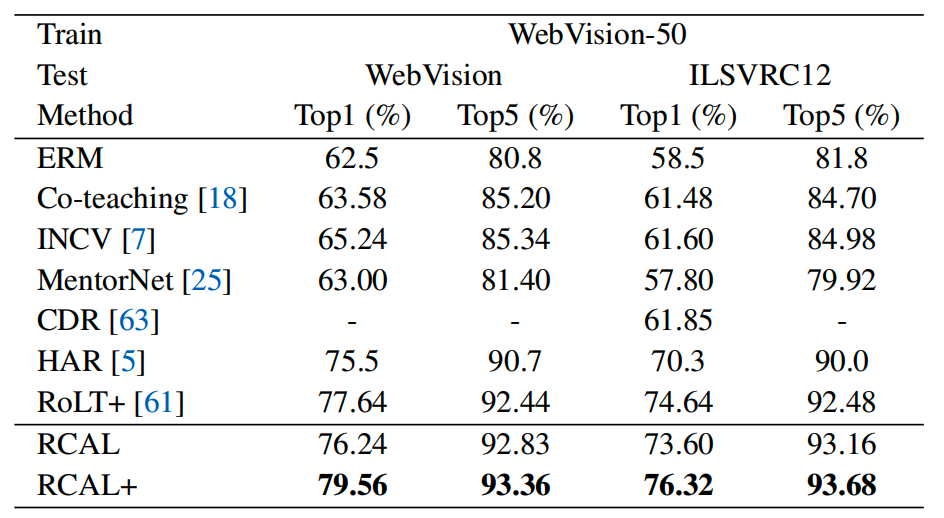
图4 WebVision和ImageNet ILSVRC12 的测试准确度
该研究进行了多种消融实验,探究算法有效的原因。
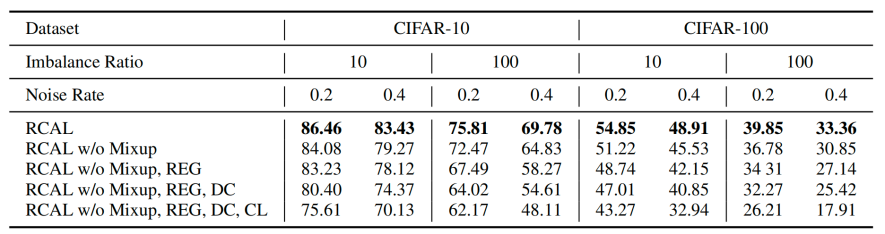
图5 消融实验
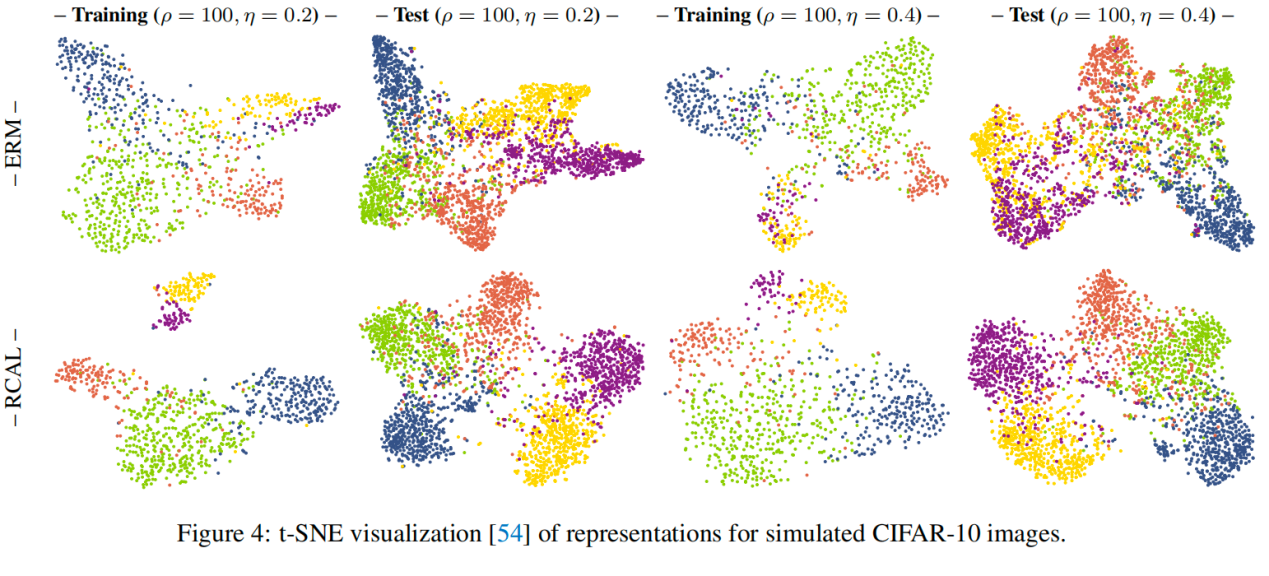
图6 t-sne 可视化下的表征

图7 ICCV 2023论文获奖候选列表
我院2021级硕士生张曼怡为该文章的第一作者,通讯作者为袁春教授,论文共同作者还包括上海交通大学黄维然副教授、华为诺亚方舟实验室姚骏、北京大学博士生赵旭阳。
论文链接:
文/图:张曼怡
编辑:万欣宜
审核:陈超群
