
12月17日,作为20周年院庆系列学术活动之一,中国计算机学会(CCF)语音对话与听觉专委会2021年学术年会在我院召开。本次年会致力于向全国语音相关领域的研究人员展示学术界和工业界的最新成果和发展趋势,促进学术界和工业界之间的交流,共同探讨学科发展的新方向。中科院自动化所陶建华,中科院核心骨干特聘研究员、中科院声学所颜永红,全国劳动模范、百度语音部门负责人及首席架构师贾磊,北京信息科学与技术国家研究中心智能科学研究部常务副主任、清华大学教授郑方,CCF语音对话与听觉专委会副主任、上海交通大学人工智能研究院语音及语言处理中心主任、思必驰公司首席科学家俞凯应邀出席活动并作报告。CCF语音对话与听觉专委会主任党建武、深圳国际研究生院执行院长高虹出席会议并致辞。现场共120余人参会,校内外共5500余人在线参会。会议由深圳国际研究生院副研究员吴志勇主持。

大会现场
会议伊始,党建武、俞凯分别致辞。高虹代表深圳国际研究生院欢迎各位嘉宾莅临我院,并预祝年会成功举行。

高虹(左)、党建武致辞
陶建华作题为“个性化语音生成和分析”的特邀报告。他介绍了当前个性化语音合成领域遇到的主要挑战及解决方案,并分享了中科院自动化所近年来在个性化语音合成方向的研究进展,包括内容与音色分离的少样本生成、韵律与音色分解的极少样本合成、一句话语音合成等工作。此外,针对合成语音可能遇到的不良使用的问题,陶建华还介绍了在生成语音鉴别领域的工作。
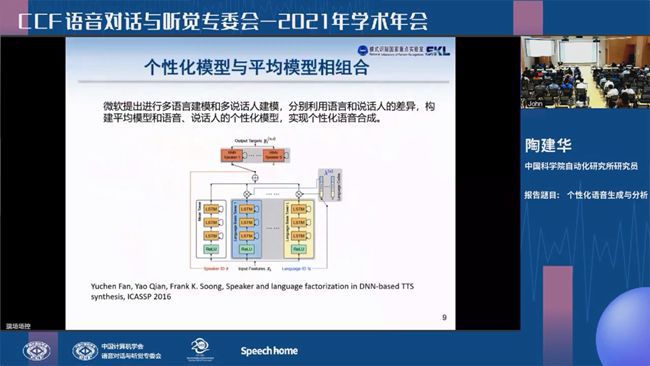
陶建华作报告
颜永红以“声学所语音识别最新进展及应用”为题,分享了声学所近年来的学术和工业成果。他表示,当前语音大规模预训练模型的出现一方面推动行业发展、降低应用门槛,另一方面也给从事人员带来新挑战。声学所一直致力于构建完全自主的技术路线,其自研的语音平台已赋能多项学术研究和业界解决方案。在近年的新冠疫情中,声学所也利用语音技术提出基于咳嗽音的新冠检测方案,虽不能作为医学标准,但在大规模快速筛查方面具有优势。
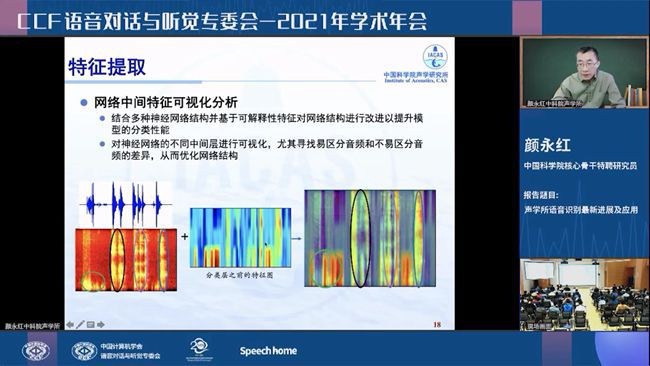
颜永红作报告
贾磊作“百度语音在建模技术、多模态和芯片方面的最新进展”主题报告,介绍了百度研发的基于流式Conformer的大规模语音识别模型SMLITA2,结合引入语言先验的PTR解码技术,实现了低延时的精准语音识别系统。贾磊还介绍了百度在自定义语音合成方向、多模态领域、智能语音交互方面的新进展。

贾磊作报告
郑方作题为“声纹识别应用的技术挑战”的报告,他表示,学术界要关注场景驱动,融合创新,将目光从技术侧转向应用侧,在应用中发现问题,再尝试使用技术去解决问题。郑方针对录音重放攻击检测和声纹掩蔽与还原的问题提出解决方案,并对多模态认证的问题进行了展望。

郑方作报告
俞凯以“语音合成中的自然韵律多样性建模”为题,系统地介绍了在韵律建模方向做出的成果。他介绍了语音韵律建模的常见思路,即使用韵律语义标签和基于参照语音的韵律模仿两种方法,并分析了两者的优劣,提出使用混合密度网络进行数据驱动的无监督韵律结构聚类,从而获得解耦出的韵律信息。俞凯提出的方法在跨说话人韵律克隆和韵律控制生成方向取得了显著效果。

俞凯作报告

嘉宾现场讨论
会后,与会师生在吴志勇的带领下参观了北京大学深圳研究生院现代信号与数据处理实验室,实验室主任邹月娴向同学们展示了实验室在多媒体信息技术处理研究方向的一系列创新成果。随后,师生一行前往深圳市北科瑞声科技股份有限公司参观。公司副总经理程刚、黄石磊分别向师生们介绍了公司发展历史和产学研合作情况,展示了其全链条音频交互技术在医疗、交通、政务和金融等行业的应用,让师生们感受到了智能语音科技“赋能”多种行业的无限可能。

师生前往北科瑞声公司参观与交流

大会合影
来源:THUHCSI人机语音交互实验室
编辑:叶思佳




