
近日,2022年国际万维网会议(Proceedings of the ACM Web Conference 2022,原名The International Conference of World Wide Web,简称 WWW’22)录用通知发布,我院信息学部夏树涛教授和江勇教授团队的5篇论文入选。国际万维网会议为CCF A类会议,汇集了国际著名大学、研究机构、跨国企业和国际标准化组织的一流学者和产业界精英,持续推动着互联网技术的发展,尤其是为各国信息化建设提供了重要的技术标准。本年度会议的主题是“展望和创造网络的未来”,论文录用率仅为17.7%,我院被录用的5篇论文聚焦于当前产业应用的痛点,在网络视频流行度预测、边缘缓存、跨模态视频检索和抵抗隐私攻击等方面提供了解决方案。

图1:文章第一作者,从上至下,从左至右为:彭俊坤、王锦鹏、唐世松、石婉欣、杨雪
《基于知识的时域融合网络进行可解释的在线视频流行度预测》(Knowledge-based Temporal Fusion Network for Interpretable Online Video Popularity Prediction),作者:人工智能项目2021级硕士生唐世松,导师:江勇教授。该论文提出了在线视频流行度预测KTFN方案。预测在线视频的流行度在现实生活中有很多应用,如推荐系统、广告营销、边缘缓存策略等。为了获得更好的预测效果,作者提出基于知识的在线视频流行度预测框架KTFN,将在线视频的元数据组织为知识图谱,并基于图注意力网络自底向上地为每个视频从邻居节点中学习到局部信息的内容特征表示。利用基于注意力的LSTM从时序数据中学习到时序特征表示。考虑到在视频的不同生命周期内,两种特征对视频流行度的影响力是动态变化的,KTFN提出一种可学习的指数衰减函数以捕捉这种动态性,并利用注意力将过滤后的特征进行融合以获得视频的最终特征表示,同时,KTFN的细腻度的学习过程提供了一定的可解释性。
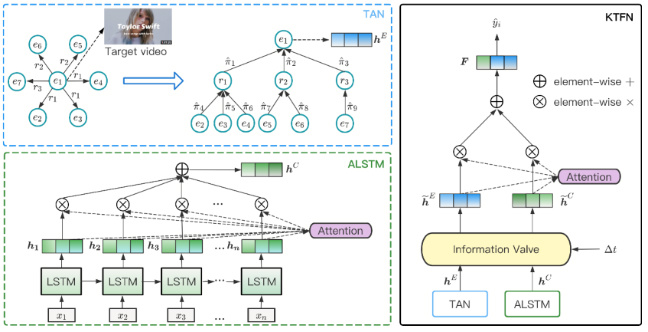
图2:KTFN框架图
《MagNet: 一种内容自动聚集的边缘协同缓存系统》(MagNet: Cooperative Edge Caching by Automatic Content Congregating),作者:计算机技术项目2020级士生彭俊坤,导师:江勇教授,本论文的研究工作与鹏城实验室李清研究员团队共同合作完成。该文章提出了分布式协同缓存MagNet方案。随着互联网内容的激增和对用户体验(QoE)的高质量需求,互联网主干网络承受着前所未有的压力。新兴的边缘缓存解决方案通过将内容缓存在更靠近用户的边缘节点来帮助缓解压力。然而,这些解决方案面临两个挑战:(1)边缘节点密度高和覆盖范围小,缓存命中率低;(2)高度动态的请求和异构的边缘节点导致边缘工作负载不平衡。在本文中,作者分析了一个典型的边缘协作式缓存场景,并进而提出了一种去中心化的分布式边缘协同缓存系统MagNet ,以应对这两个挑战。MagNet独创的内容自动聚集机制能在无需人工干预的情况下,(1)让内容在各边缘节点汇聚起来,(2)将用户的请求重定向到合适节点,并且这两者相互促进,正向循环,极大地提高了缓存命中率。MagNet的另一协同互助组机制,能够将繁忙节点和闲置节点因时因地因需自适应的组合起来,分摊工作负载,增强系统鲁棒性。
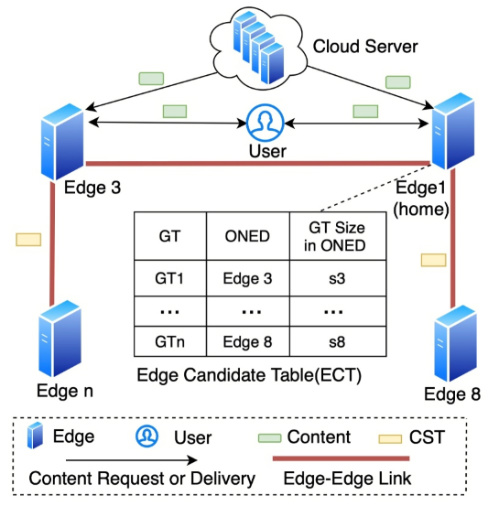
图3:MagNet系统运行框架图
《基于混合对比量化表示的跨模态视频检索》(Hybrid Contrastive Quantization for Efficient Cross-View Video Retrieval) ,作者:计算机技术项目2020级士生王锦鹏,导师:夏树涛教授。该文章提出了混合对比量化表示学习方案。为了降低视频搜索召回过程中压缩带来的语义损失和检索精度下降,本文提出一种端到端的量化表示学习的方法,称为混合对比量化表示学习。该方法分别以两个Transformers作为文本和视频的编码器,其中文本Transformer使用预训练的BERT的权重进行初始化,视频Transformer的输入是预提取的多模态特征。对于文本侧和视频侧的表示对齐,作者考虑了多粒度的对比学习。粗粒度的对齐指的是在表示汇总的tokens(如文本侧的[CLS] token和视频侧的若干个[AGG] tokens)的表示上进行对齐。细粒度的对齐通过使用一个文本侧和视频侧共享的GhostVLAD模块实现。该模块在token表示的语义空间中构建一个参数化的聚类结构,其中每个聚类都可以表达一种细粒度的语义。作者将文本Transformer的单词token的输出以及视频Transformer的视频特征token的输出,以软分配的方式分配给GhostVLAD的所有聚类。分配完毕后,对每个聚类分别计算分配的残差之和,作为整个token序列关于该聚类的细粒度表示。
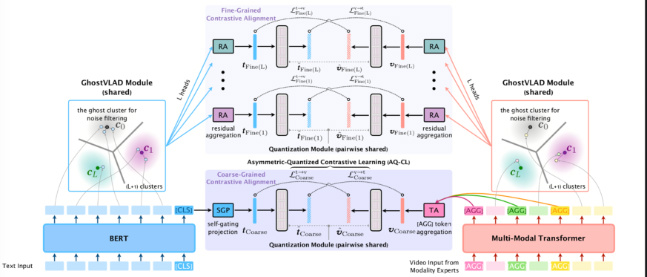
图4:混合对比量化表示学习的框架图
《基于模糊匹配的缓存优化方案LFBM》(Learning-based Fuzzy Bitrate Matching at the Edge for Adaptive Video Streaming),作者:计算机科学与技术专业2020级博士生石婉欣,导师:江勇教授。该文章提出了基于模糊匹配的缓存优化方案LFBM。在自适应码率视频的传输与播放过程中,客户端对于边缘缓存资源的信息缺失,会请求不在边缘缓存中的码率,从而造成视频资源获取速度慢、传输失败概率高。因此作者提出了一种视频码率模糊匹配方案LFBM,以进一步提高边缘缓存的利用率。边缘缓存服务器接收到视频请求时,根据客户端的播放状态以及链路状态,借助学习的方式,决策是否将视频请求转发至源服务器或选择边缘缓存中的其他码率进行响应。该方案借助Amazon EC2、开源节点PlanetLab进行了全面的实验,验证了方案的效果。
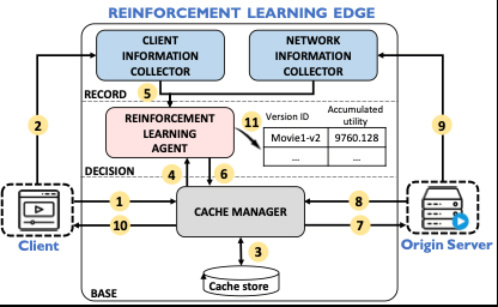
图5:LFBM系统框架
《一种用于联邦学习中抵抗隐私攻击的无损扰乱方法》(An Accuracy-Lossless Perturbation Method for Defending Privacy Attacks in Federated Learning),作者:计算机科学与技术研究所博士后杨雪(2021年12月出站),指导老师:夏树涛教授。该论文提供了横向联邦场景下高效地进行无损模型扰乱的解决方案。传统加密算法/差分隐私算法在联邦场景下,会大幅影响计算传输效率/模型精度,而该方案仅增加了常数倍的计算传输开销,就实现了准确性无损的隐私保护深度模型训练。除了模型隐私保护机制的创新外,在设定上该研究也与以往工作不同,主要考虑横向联邦场景,在服务器端可信的背景下,如何保护模型隐私安全。这也使得这篇工作有个相当有趣的潜在应用场景:在横向联邦+多数据提供方的设置下,传统联邦建模方案往往无法分离数据所有权与模型所有权。在建模过程中,数据提供商同样能够访问多方共同训练的模型,而数据需求方通常期望数据商仅提供数据,无法享受产生的价值。基于该模型扰乱训练方案,过程中服务器(数据需求方)能够获取准确的聚合梯度,客户端(数据提供商)模型迭代过程中仅能够访问加了随机噪声之后的扰乱模型,无法感知到真实的模型梯度以及模型预测结果,从而最大程度的保证模型隐私安全,即保护数据需求方的权益。
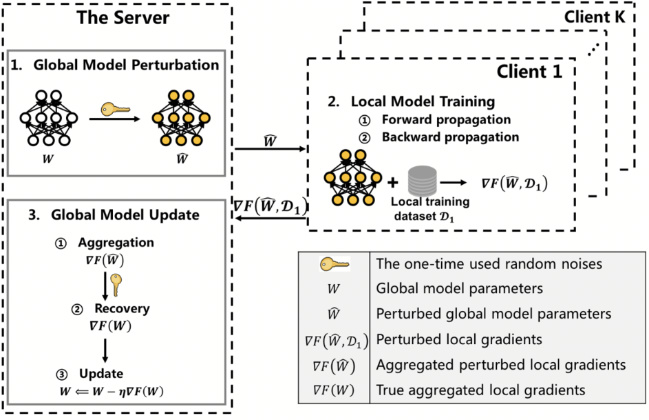
图6:无损扰乱方案框架图
文:洪明春、杨雪、石婉欣、王锦鹏、唐世松、彭俊坤
图:杨雪、石婉欣、王锦鹏、唐世松、彭俊坤
编辑:黄萧嘉




