
语音合成技术旨在根据给定的文本合成可理解的自然语音,这对于构建和谐、可靠的智能语音交互环境至关重要。智能语音交互的广泛应用对语音合成提出了新的挑战,用户希望听到的语音更具有感染力和舒适度,尤其是在有声读物、新闻播报、虚拟人等需要长篇语音的场景中。然而,现有工作局限在单一语句的语音合成中,不仅合成语音缺乏符合上下文语境的表现力,还会造成相邻语句之间说话风格出现突兀的变化。
近日,清华大学深圳国际研究生院吴志勇团队在基于风格建模的篇章语音合成领域取得新进展。研究团队提出了一种结合多模态、多语句上下文信息为篇章语音合成建模符合上下文语义且具有连贯性的说话风格的新方法。该方法同时考虑了文本侧的上下文语境信息和语音侧的历史风格信息,利用基于层级变换器(Hierarchical Transformer)的预测器,在词级别和句子级别两个层级分别建模不同模态信息之间的关系。与此同时,为了更好地学习到语音中的风格表征,团队引入了以无监督的方式预训练的风格提取器对风格预测器的训练提供指导。在此基础上,团队提出的方案可以逐句生成具有连贯说话风格和表现力的篇章语音。
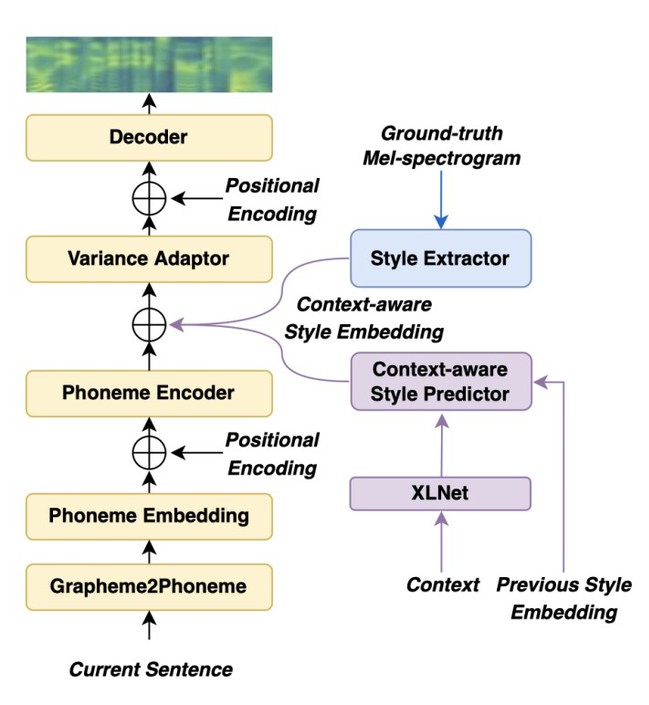
图1 模型的整体结构
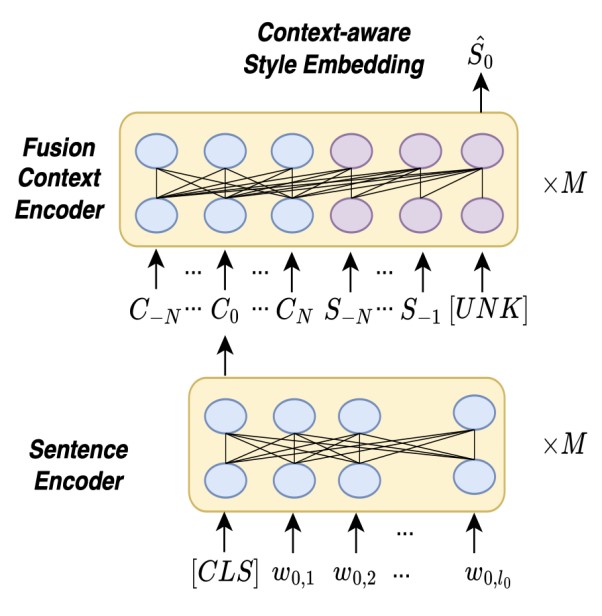
图2 上下文感知的风格预测器结构
与现有工作相比,团队提出的方法使得不论是合成单一语句还是合成篇章语音都可以提升合成语音的表现力和自然度。尤其是在篇章语音合成中,考虑到段落内各个句子说话风格之间的关系,团队提出的模型在主观意见得分上取得了进一步的提升。团队提出的模型在不需要引入人工标注的情况下无监督地学习语音的风格信息,将模型感知范围从单一语句、文本模态提升到了多个语句、多个模态,并在单一语句和篇章语音的合成上都优于现有语音合成方法,是迈向篇章语音合成的一大突破。
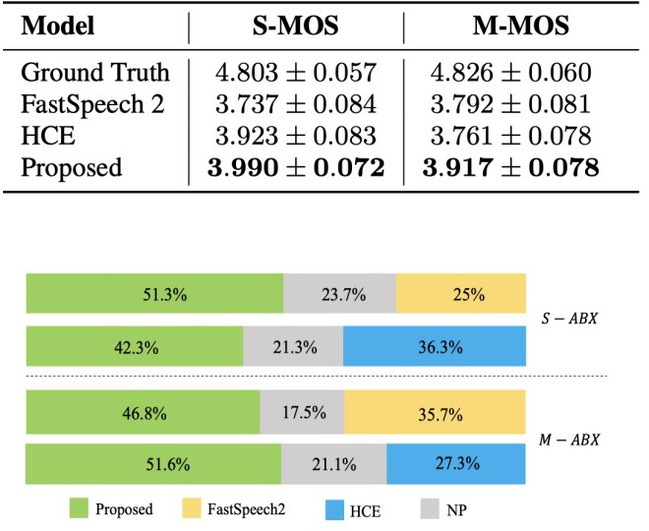
图3在单一语句合成和篇章合成实验
相关研究成果近日以“面向有声读物合成的上下文感知连贯性说话风格预测方法”(Context-aware Coherent Speaking Style Prediction With Hierarchical Transformers for Audiobook Speech Synthesis)为题,被“IEEE声学、语音与信号处理国际会议”(2023 IEEE International Conference on Acoustics, Speech, and Signal Processing)录用为口头报告(Oral),并入选TOP 3%论文。

图4 Top 3%论文认证证书
清华大学深圳国际研究生院2021级硕士生雷舜和2020级硕士生周逸轩为该文章的共同第一作者,通讯作者为清华大学深圳国际研究生院吴志勇副研究员,论文共同作者还包括清华大学深圳国际研究生院2021级博士生陈礼扬,元象唯思控股(深圳)有限公司康世胤博士和香港中文大学系统工程与工程管理学系蒙美玲教授。该研究成果得到了国家自然科学基金委员会、深圳市科技创新委员会、鹏城实验室等部门和单位的支持。
论文链接:https://ieeexplore.ieee.org/abstract/document/10095866
文/图:雷舜
编辑:戴雨静
审核:陈超群




