
专利示意图
一、技术领域
人工智能技术领域
二、专利介绍
1.专利信息
专利类型:发明
专利权人:清华大学深圳国际研究生院
申请号:202210999098.0
发明人:梁耀元、唐彦嵩、樊家硕、黄绍伦
2.专利说明书摘要
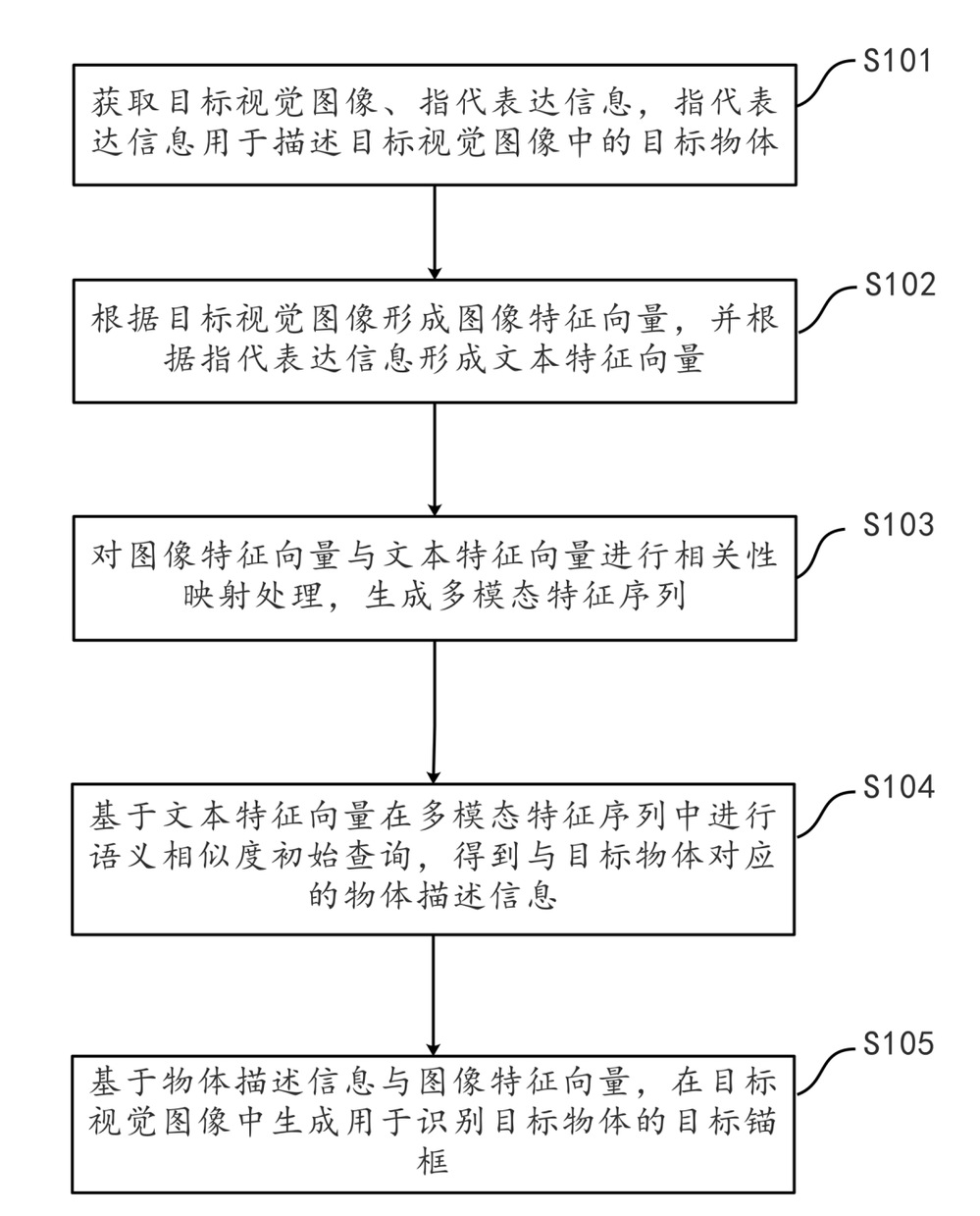
本申请涉及人工智能技术领域,尤其是涉及一种目标识别方法及其模型、电子设备、存储介质。本申请目标识别方法中,需要先获取目标视觉图像、指代表达信息,再根据目标视觉图像形成图像特征向量,并根据指代表达信息形成文本特征向量,进一步,对图像特征向量与文本特征向量进行相关性映射处理,生成多模态特征序列,进而基于文本特征向量在多模态特征序列中进行语义相似度初始查询,得到与目标物体对应的特征描述向量,最终基于特征描述向量与图像特征向量,在目标视觉图像中生成用于识别目标物体的目标锚框,能够在视觉图像中对指代表达所描述的物体做到较为精确的定位,以提升目标识别的准确率。
3.创新点
(1)本发明针对图像指代描述理解 (REC)任务,设计并提出了在Transformer架构下引入一系列锚框作为语言表述提供的位置先验来更好的定位文本所指代的物体的方法和模型;
(2)本发明提出了的新的解码策略,设计并实现了原型解码器和连续锚框引导的解码器解耦自然语言表述中包含的语义和位置信息,利用多模态上下文语义信息相关性迭代式更新初始锚框以得到最后预测的指代物体所在区域。无需手工设计的锚框即可利用物体位置先验加速模型学习速度;
(3)本方法定位精度高于已有同类方法,是一种很有潜力的图像指代描述理解方法。
4.痛点问题
(1)目前基于Transformer的图像指代描述模型在解码时只利用了语言表述的语义信息,忽略了语言表述中的位置信息,本发明解耦了语言的语义和位置信息进行解码;
(2)本发明无需引入手工设计的锚框即可引入可学习的位置先验,加速了模型的训练速度。
5.技术优势
(1)本技术引入了语言的位置先验,大大提高了指代物体定位精度。
(2)通过在位置预测中引入可学习的锚框,无需手工设计的锚框即可引入语言的位置先验,同时也能提高模型的训练稳定性和速度,对应用于安防监控,图像搜索等有其重大意义。
(3)本方案模型收敛速度快,模型结构简单,有效节约时间和人力设备成本。
三、产业化信息
1.应用场景
(1)用于安防监控根据自然语言描述定位人或物体的场景;
(2)用于在图片/视频编辑里面,准确分割出任意指代目标物体;
(3)用于人机交互中指代物体定位。
2.商业价值
此项技术拥有巨大的商业前景,对于互联网服务行业有以下市场价值:
(1)本技术可以有效提高检测指代描述物体的准确性,尤其在复杂图片场景下能够大大提高定位准确率;
(2)此技术可以在视频监控或机器人的视频流中根据监测者提供的指代描述检测出对应的目标(人物或物体),具有较大的应用价值。与之前的方法RefTR相比,无需引入手工设计的锚框即可更精准的定位目标物体。
3.发展规划
(1)该技术未来可应用于定位图片或视频流中一个或多个指代物体,快速提高我国在智慧安防等人工智能领域的水平;
(2)该技术通过推广多模态图像指代理解的研究与应用、基于深度学习的物体检测定位研究与服务等方式均可能占据市场。
4.合作方式
面议
注:所有成果未经授权,请勿转载
联系方式:ttc@sz.tsinghua.edu.cn




