
专利示意图
一、技术领域
多媒体数据部署技术领域
二、专利介绍
1.专利信息
专利类型:发明
专利权人:清华大学深圳国际研究生院
申请号:202210880715.5
发明人:毛忆南、周仕佶、路荣伟、王智、朱文武
2.专利说明书摘要
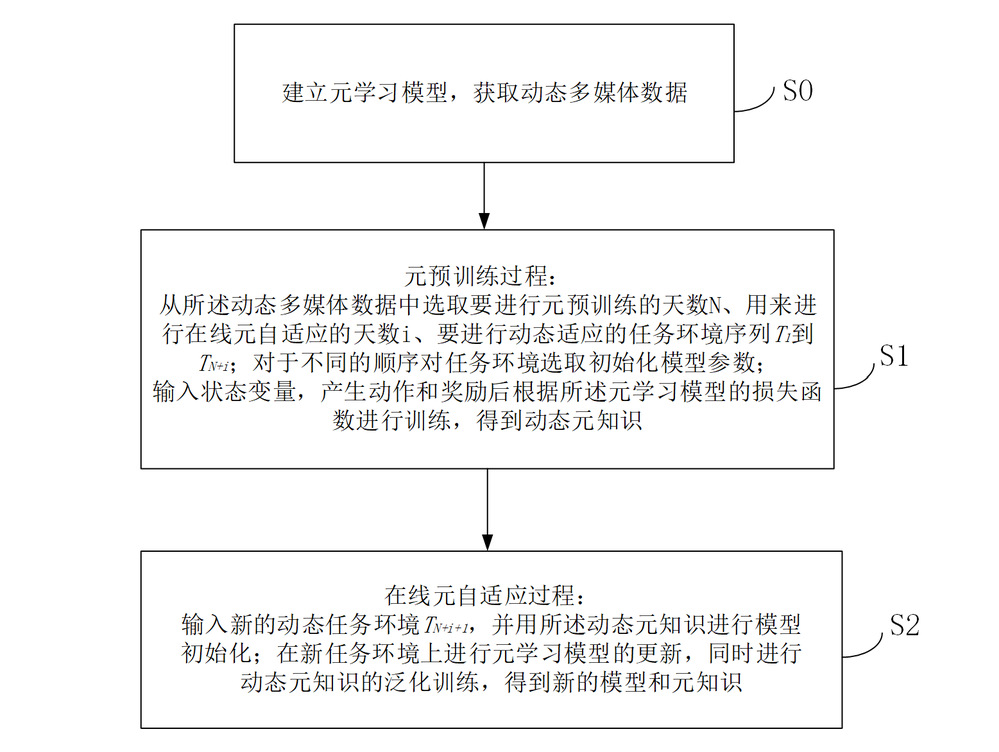
本发明公开了一种基于强化学习的动态多媒体数据部署方法,包括:建立元学习模型,获取动态多媒体数据;元预训练过程:从动态多媒体数据中选取要进行元预训练的天数N、用来进行在线元自适应的天数i、要进行动态适应的任务环境序列;对于不同的顺序对任务环境选取初始化模型参数;输入状态变量,产生动作和奖励后根据元学习模型的损失函数进行训练,得到动态元知识;在线元自适应过程:输入新的动态任务环境,用动态元知识进行模型初始化;在新任务环境上进行元学习模型的更新,进行动态元知识的泛化训练,得到新的模型和元知识。本发明能够在不断变化的视频流行度下,避免边缘内容缓存命中率因为动态请求模式导致的性能下降。
3.创新点
(1)我们提出了一个在线元强化学习(OMAC)框架来解决动态边缘缓存问题。为了验证OMAC的有效性,我们使用来自爱奇艺和快手的真实数据记录(脱敏用户信息)进行了全面的实验,实验结果表明,我们的解决方案始终产生比基线更好的优化效果;
(2)特别是,我们的设计在所有56个随机选择的边缘区域中实现了最佳性能,并且在爱奇艺和快手跟踪中分别实现了16.3%和37.4%的平均命中率提高;
(3)为了评估稳健性,我们针对不同的缓存大小和边缘服务区域评估我们的OMAC。实验结果表明,我们的解决方案在每种情况下都保持了最佳性能;
(4)我们的消融研究还表明,序列对设计和在线更新都有助于提高性能。
4.痛点问题
(1)在不断变化的视频流行度下,避免边缘内容缓存命中率因为动态请求模式导致基于强化学习框架的缓存方法的性能下降,并且完善元强化学习框架在缓存问题上的策略;
(2)捕捉动态变化的序列对元知识,以及保持元知识在线更新,更快地使模型适应边缘动态环境。
5.技术优势
(1)本发明准确将边缘内容缓存上的动态请求分布建模为马尔科夫决策过程,提高基于模型方法的泛化能力;
(2)本发明通过依赖于先前历史知识的梯度估计充分利用当前信息,导致边缘缓存模型训练具有更好的收敛效果;
(3)本发明避免使用手工设计的启发式工作,获得的元知识适用于边缘缓存环境的动态情况,具有更好的泛化性能和内容命中率结果。
三、产业化信息
1.应用场景
(1)用户使用场景1:在边缘端更为动态和非平稳的数据分布环境下,实现深度学习模型能够更快速进行泛化,适应边缘的数据分布,使得决策模型及时提供有效服务;
(2)用户使用场景2:在内容分发网络中,根据不同地区内容的流行度特征,预估用户感兴趣的内容,提前将内容分发到能够提供较好体验的服务器上,降低用户的等待延迟。
2.商业价值
近年来,我们见证了边缘辅助内容分发基础设施的快速发展和建设。视频流近年来实现了飞速增长,在2020年占整个互联网流量的80%,预计到2022年底将翻两番。将内容复制和分发模块移动到互联网(或网络)的边缘端有可能减轻骨干网的工作量并提高视频流用户的体验质量(QoE)。这种视频内容服务通常被称为边缘内容分发。尽管确切的名称在业界仍有争议,但边缘内容交付发生了根本性的变化。
随着视频平台的快速变革,与传统的相比,边缘服务器中的请求模式更加动态和分散。例如,我们对最著名的短视频共享平台之一的快手的测量研究表明,与传统视频相比,Kullback-Leibler(KL)散度测量的天数之间的内容请求模式差异增加了35.1%,从23.30到31.47基于共享平台。这表明内容流行度随时间变化很大,尤其是对于短视频平台。这主要是因为边缘缓存通常只专用于一小部分用户。
这种动态请求模式对边缘内容分发中现有的内容缓存方法提出了挑战:1)具有先验假设的传统方案,包括最近最少使用(LRU)、最不常用(LFU)及其变体,都很难及时适应动态环境,因为它们基于简单的基于规则的策略和一些手动设置的参数特性。2)基于强化学习(RL)的缓存策略已被验证可实现比传统的基于规则的策略更高的命中率。然而,它们的设计假设是静态和平稳环境,而这种假设与当前内容模式的动态相矛盾,并且已经通过我们的测量得到了说明。当应用于动态边缘内容分发时,无法保证这一假设,这通常会导致性能下降。一个可能的原因是动态请求模式会逐渐削弱静态假设,导致假设与现实世界的请求模式之间的差距越来越大。因此,过时的历史数据不断降低强化学习模型的实时性能。3)对基于强化学习的方法的改良研究,包括使用手动特征的方法和其他使用递归网络架构来提取动态特征的方法,仍然受到环境急剧变化的影响。
一个直接的解决方案是重新启动强化学习模型,以摆脱过时数据的长期影响。然而,强化学习模型需要很长的适应时间才能获得良好的性能,因此我们需要另一个框架来加速这一过程。为了实现更快的适应,我们考虑在处理新的动态任务时为强化学习模型提供一些可转移的知识。面对上述挑战,元强化学习有望成为一个有前途的解决方案,因为它已被证实可以在以往的工作中实现对新环境的极大适应。然而,我们发现在这种情况下,简单地使用元强化学习甚至会比普通强化学习方法表现更差。2.一种可能的解释是,普通的元强化学习会忽略时间域中的动态特征(元强化学习任务是为多任务适应目的而学习,没有时间序列序列设计,而缓存问题显然是按时间序列排列的),因此,不适合边缘缓存问题。
如何让元强化学习适应这种动态环境?我们在这里给出两个关键的设计目标:1)元学习应该捕捉时间可转移的知识,以适应动态环境;2)元知识应不断更新以保持及时性。为了实现1),我们通过将动态情节分割成一系列短间隔来重新制定元强化学习,然后利用元强化学习从序列对区间获取动态变化的知识。对于2),我们提出了一种基于在线梯度下降(OGD)的在线元学习范式,以保持元强化学习的知识新鲜度。
3.发展规划
(1)该技术未来可应用至更多的元知识场景,首先根据原始系统的内容请求数据,使用针对动态缓存任务元知识设计的顺序对元损失函数来进行元预训练过程(通过序列对任务获取元知识),使用少量历史请求序列来联合更新得到初始元知识;
(2)在边缘计算领域获得更多的关注和应用,将边缘缓存内容分发问题定义中的状态空间,动作空间,奖励函数等进行定义。使用来自相邻时间序列的内容请求数据,进行基于元学习的双层优化训练,通过AGAE(Generalized Advantage Estimation)获得在前后相邻任务中的可转移信息;
(3)更有利于在线场景的成果转化,使用在线的方式更新元知识,并保持其长期影响进行在线元适应(刷新元知识),通过多步在线梯度下降(OGD)更新元知识旨在找到一些通用特征,并获得可迁移的元知识以帮助智能体获得更好的适应规则。
4.合作方式
面议
注:所有成果未经授权,请勿转载
联系方式:ttc@sz.tsinghua.edu.cn




