
2018年以来,预训练语言模型(PLM)及其“预训练-微调”方法已成为自然语言处理(NLP)任务的主流范式,该范式先利用大规模无标注数据通过自监督学习预训练语言大模型,得到基础模型,再利用下游任务的有标注数据进行有监督学习微调模型参数,实现下游任务的适配(图1)。越来越多实验表明:规模越大的模型不仅在已知任务上有更好的表现,同时展现出完成更复杂的未知任务的强大泛化能力,近年出现的GPT-3、ChatGPT等均为大规模预训练模型的代表。然而,现有对大规模预训练模型的全部参数进行微调实现任务适配的做法,会消耗大量的GPU计算资源和存储资源,严重限制大模型的应用场景。为了应对该挑战,参数高效微调(Parameter-efficient Fine-tuning)方法逐渐受到关注。与全参数微调相比,参数高效微调方法冻结预训练模型99%以上的参数,仅利用少量下游任务数据微调少于1%模型规模的参数,作为模型插件实现大模型对下游任务的适配,达到媲美全参数微调的性能,并显著降低微调过程的计算和存储开销。
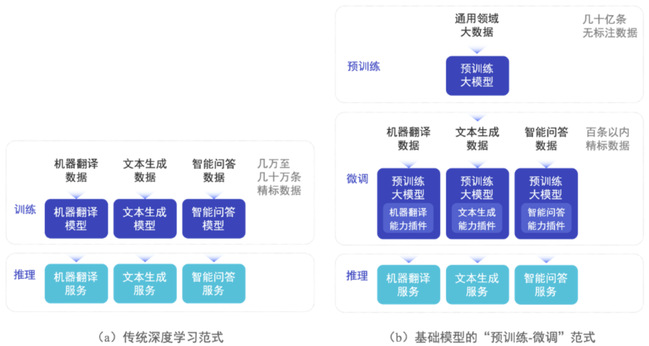
图1 基础模型的“预训练-微调”范式与传统深度学习的对比
清华大学深圳国际研究生院郑海涛团队提出,参数高效微调方法的本质是在对“增量参数”(Delta Parameters)进行调整,因此将此类方法命名为“增量微调”(Delta Tuning),并基于统一的分析框架对增量微调现有方法进行梳理总结,将现有方法分为三类(如图2所示):添加式(Addition-based)、指定式(Specification-based)和重参数化(Reparameterization-based)方法。为了指导后续的模型架构和算法设计,团队还进一步从参数优化和最优控制两个角度,提出了增量微调的理论框架,为探索和解释增量微调的内在机理提供了可行方案。
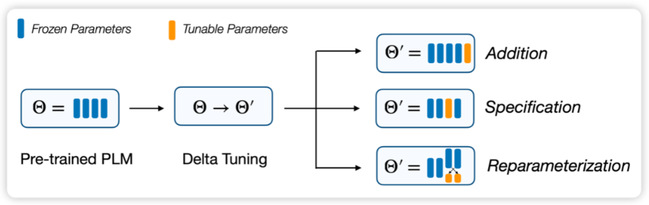
图2 统一视角的增量微调框架
该研究工作选择了超过100个自然语言处理任务,对主流增量微调方法进行了全面细致的性能比较和分析,得出多项重要结论,例如:(1)基础模型随着参数规模的不断增大,在性能显著提高的同时,不同增量微调方法的差异急剧减少(图3),最少仅需要优化万分之八的模型参数即可完成适配;(2)不同增量微调方法可以进行并行或者串行的组合从而达到更优的性能,表明了分布在模型参数空间中的智能能力可以进行组合和泛化;(3)增量微调方法具备良好的任务级别的迁移能力,完成特定任务的“能力”可以表示为轻量级参数化的形式,可以在不同基础模型和不同用户之间共享。以上研究表明,增量微调是基础模型的重要特性,上述结论将加深对基础模型的认识,为其创新研究与应用提供重要支撑。
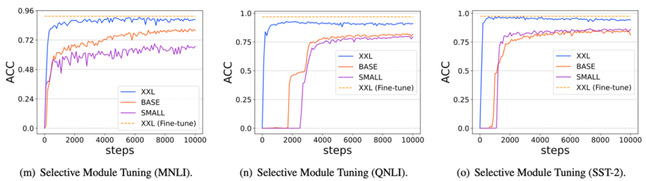
图3 随着基础模型参数规模的增大,增量微调方法可以更有效地激发模型性能
研究团队自2018年以来坚持开展语言大模型创新研究,并坚持建设OpenBMB开源社区,致力于构建大规模预训练模型全流程高效计算工具体系,相关工作在全球最大的开源社区GitHub上累计获得超过4000星标关注,曾获自然语言处理领域著名国际会议ACL 2022最佳系统演示论文奖等荣誉。研究团队基于该论文成果研制发布了开源工具包OpenDelta,是OpenBMB开源社区的重要组成部分,可支持研究者和开发者灵活高效地在各类预训练模型上实现和应用增量微调方法。研究团队认为,增量微调技术将是基础模型适配特定任务、场景和用户的重要范式,可更有效地激发以ChatGPT为代表的大规模预训练模型的性能。
相关研究成果以“面向大规模预训练语言模型的参数高效微调”(Parameter-efficient Fine-tuning of Large-scale Pre-trained Language Models)为题作为封面文章发表在国际期刊《自然·机器智能》(Nature Machine Intelligence)。
该研究成果由清华大学深圳国际研究生院郑海涛团队师生及清华大学计算机系孙茂松教授、李涓子教授、唐杰教授、刘洋教授、陈键飞助理教授、刘知远副教授共同完成,刘知远、郑海涛、孙茂松为该文章的共同通讯作者,清华大学深圳国际研究生院2018级博士生丁宁与清华大学2019级博士生秦禹嘉为该文章的共同第一作者。该研究得到科技部科技创新2030“新一代人工智能”重大项目、国家自然科学基金、北京智源人工智能研究院、清华大学国强研究院的支持。
论文链接:
https://www.nature.com/articles/s42256-023-00626-4
编辑:林洲璐
视频:戴雨静
审核:陈超群




