
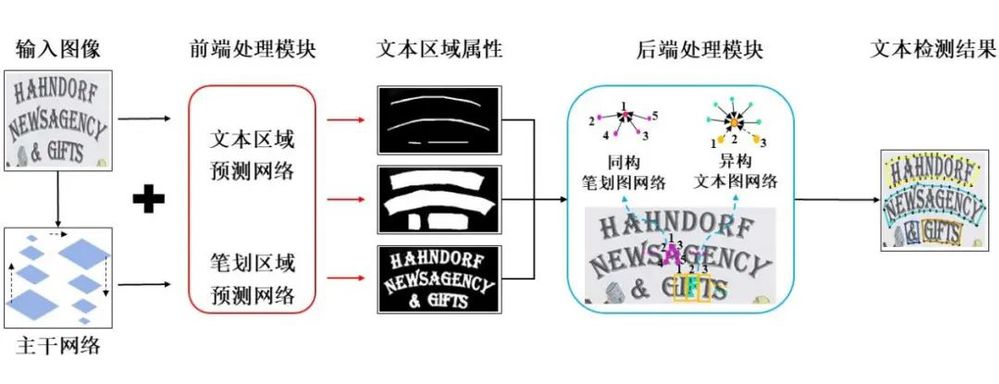
专利示意图
一、技术领域
视觉文本检测技术领域
二、专利介绍
1.专利信息
专利类型:发明
专利权人:清华大学深圳国际研究生院
申请号:202310617471.6
发明人:袁春、李磊
2.专利说明书摘要
一种基于笔划区域分割策略的视觉文本检测方法,包括如下步骤:S1、通过基于卷积神经网络的前端处理模块,针对输入的文本图像执行特征提取和多级区域预测;S2、依据文本区域的多级预测结果提取文本级和笔划级的区域候选框,进而构建层次化的局部图结构;S3、通过基于图神经网络的后端处理模块,在各个局部图执行基于多级图节点的节点特征聚合和关系推理,推断不同级别图节点之间的关系并进行链接预测,将节点进行分组进而组成整体的文本实例检测结果。在视觉文本检测研究领域广泛采用的标准评估数据集上进行了实验,验证了本发明视觉文本检测方法的有效性、高精度和良好的泛化能力。
3.创新点
(1)本发明涉及计算机视觉文本图像检测与OCR图像翻译等领域,针对现有方法通常难以精确定位任意形状的文本实例以及难以有效辨别、分离出互相靠近的多个文本实例的情况,提出一种基于笔划区域分割策略的高精度视觉文本检测方法;
(2)本方法提出一个轻量级的笔划分割预测网络,作为对当前主流文本检测器仅能实现文本区域预测的有效补充,从而实现检测模型对于文本区域的多级(文本级、笔划级)表示;
(3)本专利引入了一个新型的视觉图像数据集(SceneText),其每个图像样本中的文本实例都标注有笔划级别的分割标签,即二值化笔划字符分割图。该数据集将通过预训练检测框架中基于卷积神经网络的前端处理模块来提升检测框架对于文本区域多级表示的预测准确性;
(4)本专利引入一种新型的图神经网络模型,其作为所构建的文本检测框架中的后端处理模块,能够有效针对前端处理模块预测得到的文本区域的各个部分执行特征聚合和关系推理,使得改进后的图模型可以更好地适应文本检测任务场景;
(5)本方法精度高于已有同类方法,是一种很有潜力的视觉文本图像检测方法。
4.痛点问题
(1)难以精确定位任意形状的图像文本实例;
(2)难以有效辨别和分离出互相靠近的同一文本图像中的多个文本实例;
(3)算法耗时过长。
5.技术优势
本发明中提出的文本检测方法可以对于文本区域执行笔划级别的分割预测,该分割预测结果结合传统方法的文本检测结果可以满足更多业务功能的需求,如图像修复、OCR翻译等。
三、产业化信息
1.应用场景
(1)电子收据、发票等视觉文本图像中的文字检测与识别等操作;
(2)文本图像修复系统的前端处理(文本分割与检测)模块;
(3)OCR图像翻译系统的前端处理(文本分割与检测)模块。
2.商业价值
此项技术拥有较为广阔的商业前景,对于电商行业有以下市场价值:
本方法可以通过提升文本内容识别与文本实例检测精度来有效提升OCR技术的效率与可靠性,从而大大降低企业中相关业务的人工与资源成本。
3.发展规划
该技术未来可应用至电商等领域(如交易支付系统中的电子发票)的文本图像检测与OCR图像翻译等场景,提升文本图像处理相关领域信息理解与处理效率。
4.合作方式
面议
注:所有成果未经授权,请勿转载
联系方式:ttc@sz.tsinghua.edu.cn




